
In meinem letzten Blogpost zum Thema große Sprachmodelle (LLMs) habe ich die Frage gestellt (und beantwortet), wie Unternehmen auf Basis der vorhandenen LLMs ihre eigenen KI-Anwendungen „bauen“ können, ohne dabei wichtige Unternehmensprinzipien zu vernachlässigen. Zu denen gehören zweifellos der Datenschutz, die Zuverlässigkeit und Aktualität der zugrunde liegenden Daten.
Ein Ausweg aus den möglichen Dilemmas nennt sich Retrieval-Augmented Generation (RAG), eine Technik, die bestehenden Sprachmodelle wie ChatGPT mit eigenen Datenbanken bestmögliche zu kombinieren. Der heutige Beitrag soll zeigen, welche weiteren Möglichkeiten bestehen, und das mit der Hilfe von Intel und deren Technologiepartnern.
Zunächst einmal sei gesagt, dass sich Intel seiner Verantwortung rund um das Thema generative KI und all seinen Auswirkungen sehr bewusst ist und daher es auch sehr ernst nimmt. Aus diesem Grund unternimmt der Chiphersteller kontinuierlich weitreichende Anstrengungen, um gerade die Risiken, die von bestehenden und häufig benutzten Sprachmodellen und anderen KI-Daten ausgehen, so gut wie möglich zu reduzieren. Oft geschieht das mit Technologiepartnern wie zum Beispiel Prediction Guard, Seekr, Storm Reply und Winning Health Technology, von denen heute die Rede sein soll. Diese Liste ließe sich natürlich beliebig erweitern.
Prediction Guard: Mehr Datenschutz in KI-Applikationen
Mit dem Startup-Unternehmen Prediction Guard hat sich Intel das geballte Wissen rund um die Datensicherheit und -hoheit von KI-Anwendungen quasi an Bord geholt, indem Daniel Whitenack und sein Team schon eine ganze Weile ein wichtiger Teil des Intel Liftoff-Programms für KI-Startups ist. Das Besondere an der Prediction Guard-Lösung ist ihre relativ unkomplizierte Integration in bestehende KI-Unternehmenslösungen, die einerseits die Power bestehender LLMs nutzen wollen, aber andererseits sorgsam mit bestehenden Daten umgehen.
Mit Prediction Guard können existierende Unternehmensapplikationen auf mögliche Schwachstellen hin untersucht werden, was den Einsatz der zugrunde liegenden LLMs betrifft. Dies geschieht ganz einfach per zeilenbasierten Abfragen, wie sie von Anwendungen wie ChatGPT bekannt sind. Kollidiert das eingesetzte Sprachmodell mit geltendem Recht? Gibt es möglicherweise Geschäftsgeheimnisse preis? Diese und weitere Fragen lassen sich mittels einfacher Fragen interaktiv beantworten.
Seekr: KI-Plattformen implementieren und Podcasts analysieren
Mit seekrAlign und seekrFlow lassen sich mit relativ wenig Know-how komplette KI-Plattformen und -Applikationen erstellen sowie mit Leben füllen, ohne dass sich Unternehmen Gedanken über das „Wie“ machen müssen. Nicht ohne Grund setzen multinationale Unternehmen wie Oracle und Babbel auf die Möglichkeiten, die beide Seekr-Lösungen bieten. Hierzu entsteht mit seekrFlow in einem ersten Schritt eine sichere KI-Anwendung, und das auf Basis der vorhandenen Daten. Dies geschieht auf jedweder Hardware-Plattform, für die seekrFlow konzipiert und optimiert wurde. Das Besondere daran ist die Möglichkeit, mithilfe einfacher Zeilenbefehle die Applikation nach ihrer ersten Erstellung weiter zu verfeinern.
SeekrAlign auf der anderen Seite wendet sich an Werbetreibende, Verleger und Betreiber von Marktplätzen, die mithilfe geeigneter Podcasts und anderer Mediaformate ihre Reichweite auf sichere und zuverlässige Art und Weise vergrößern wollen. Dabei werden sie von KI-Funktionen wie Seekr Civility Score bestmöglich unterstützt, und das mit einem Höchstmaß an Transparenz.
Storm Reply: Optimierte AWS-Instanzen für bestmögliches Inferenzieren
Als ein langjähriger AWS Premier Consulting Partner weiß Storm Reply genau, worauf es bei Public Cloud-Services ankommt. Ein Dienst hierbei hat mit dem Implementieren von großen Sprachmodellen (LLMs) auf den Amazon Elastic Compute Cloud (EC2) C7i-und C7i flex-Instanzen zu tun. Dort kommen Intel Xeon Prozessoren der 4. Generation zum Einsatz, und das in Kombination mit Intel Libraries, die speziell für das Erstellen und Verwalten von Sprachmodellen (LLMs) konzipiert sind. Obendrein profitiert Storm Reply von der Intel GenAI-Plattform und dem Open-Source-LLaMA-Modell (Large Language Model Meta AI). Damit sind RAG-basierte KI-Applikationen möglich.
Winning Health Technology: Angepasste LLMs für das Gesundheitswesen
Das gesamte Gesundheitswesen kann einer der Gewinner sein, wenn es um den Einsatz von generativer künstlicher Intelligenz geht. Hierfür sind allerdings große Sprachmodelle (LLMs) erforderlich, die leistungsfähige Compute-Plattformen benötigen, woran es gerade im Gesundheitswesen häufig mangelt. Genau diesem Umstand trägt ein Sprachmodell namens WiNGPT Rechnung, das Winning Health Technology entwickelt hat.
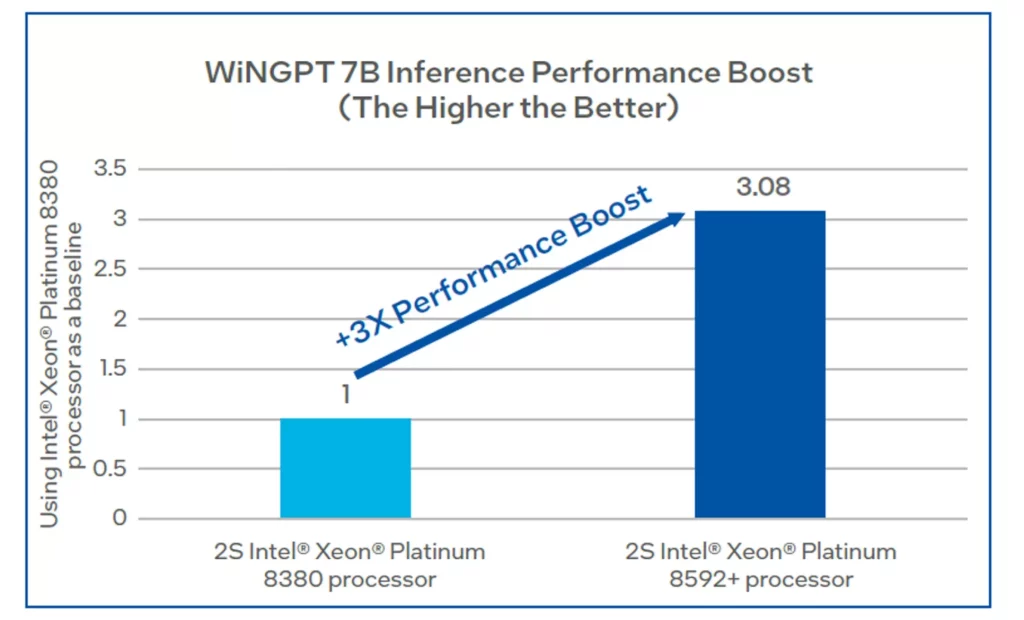
Dieses auf das Gesundheitswesen zugeschnittene LLM wurde speziell für den Einsatz auf Intel-basierten Großrechnern angepasst und optimiert. Herausgekommen ist ein Sprachmodell, das auf Intel Xeon Prozessoren der 5. Generation 3x schneller inferenziert als auf derselben CPU der 3. Generation. Ein wesentlicher Grund hierfür ist der intensive Einsatz bestimmter KI-Beschleuniger wie Intel AMX (Advanced Matrix Extensions).
Disclaimer: Für das Verfassen und Veröffentlichen dieses Blogbeitrags hat mich die Firma Intel beauftragt. Bei der Ausgestaltung der Inhalte hatte ich nahezu freie Hand.