
Aufwändige KI-Modelle und -Anwendungen erfordern immer mehr Daten, damit sie überhaupt die bestmöglichen Ergebnisse erzielen können, speziell im Umfeld von sogenannten LSTM-Anwendungen (Long Short-Term Memory (LSTM, zu deutsch: langes Kurzzeitgedächtnis). Um genau dieses Dilemma erheblich zu reduzieren, hat das US-Unternehmen Numenta gemeinsam mit Intel den hierfür passenden Weg gefunden. Dieser Beitrag zeigt, wie das genau funktioniert.
Seit nunmehr fast 20 Jahren beschäftigen sich die Numenta-Gründer Donna Dubinsky, Jeff Hawkins und Dileep George mit neuronalen Algorithmen und Modellen. Dabei fiel ihnen irgendwann auf, dass das menschliche Gehirn den aktuellen Rechenmaschinen in einem Punkt nach wie vor überlegen ist: Es kann schneller die wichtigen von den unwichtigen Parametern unterscheiden, und das in kürzester Zeit und ohne größeren Trainingsaufwand.
Einfach, weil unser Gehirn sehr viel paralleler funktioniert als ein Prozessor. Denn diese basieren nach wie vor auf sogenannten Dense-Modellen, bei denen die vorhandene Rechenkapazität vor allem dafür genutzt wird, arithmetische Operationen an Parametern durchzuführen. Das ist oft sehr ineffizient und verschwendet wertvolle Rechenzeit.
Sparse-Modelle erfordern eine hohe Rechenparallelität
Im Gegensatz dazu fokussieren sich Sparse-Modelle vor allem auf die Parameter, die vermeintlich für das Lösen des jeweiligen Computerproblems erforderlich sind. Hierfür ist allerdings ein hoher Parallelitätsgrad erforderlich, mit dem die Algorithmen einerseits und die riesigen Datenmengen andererseits verarbeitet werden können.
Diese Disziplin beherrschen Standard-Prozessoren zwar schon eine ganze Weile sehr gut, im Vergleich zu den aktuellen GPUs (Graphics Processing Unit) sind sie allerdings nach wie vor eher lahm. Zudem sind Grafikchips wie der Nvidia A100 im Vergleich zu einem Intel Xeon Prozessor deutlich teurer und stellen zudem die IT-Administratoren vor zusätzliche Herausforderungen.
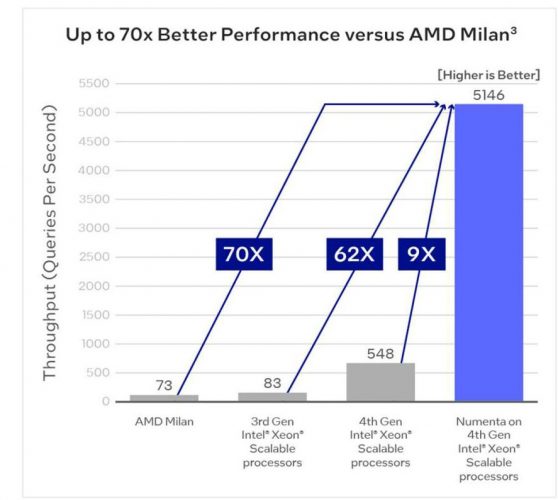
Genau diesem Gedanken liegt die KI-Plattform von Numenta zugrunde, die es dank des hohen Parallelitätsgrads schafft, herkömmliche Prozessoren wie die AMD Milan CPUs im direkten Vergleich mit dem Intel Xeon Prozessor der 4. Generation um den Faktor 70 hinter sich zu lassen.
Das bedeutet konkret, dass ein AMD Milan CPU-basierter Rechner bei derselben Zahl an Datenabfragen auf einen Wert 70 kommt. Im Vergleich dazu schafft eine Rechenmaschine, die mit dem Intel Xeon Prozessor der 4. Generation ausgestattet ist und obendrein die Numenta-Anwendung NuPIC nutzt, auf einen Wert von 5.146, was einem 70-fach höheren Durchsatz entspricht. Doch wie ist solch ein enormer Unterschied überhaupt möglich?
Die Kombination aus Intel AMX und Intel AVX-512 macht den Unterschied
Das Besondere an den zugrunde liegenden NuPIC-Algorithmen ist eine Kombination aus Intel AMX (Intel Advanced Matrix Extensions) und Intel AVX-512 (Intel Advanced Vector Extensions 512). Das eine (Intel AMX) stellt eine in die CPU integrierte Beschleunigerfunktion dar, die ihre Stärken vor allem im Bereich des neuronalen Lernens von KI-Datenmodellen ausspielt. Intel AVX-512 wiederum ist ein für Hochleistungsalgorithmen entwickelter und optimierter Befehlssatz, der speziell in Vektor-basierten Berechnungen großen Nutzen stiftet. Und genau darum geht es bei Numenta.
So wird beispielsweise Intel AMX dazu genutzt, Daten in ein Fließpunktdatum mit einer Länge von 32 Bit zu konvertieren, woraus mithilfe Intel AVX-512 ein Gleitkommadatum mit einer Länge von nur noch 16 Bit entsteht (auch genannt BFloat16), das anschließend in Intel AMX zurücküberführt wird. Daraus resultiert ein Datum, das deutlich kleiner ausfällt, allerdings denselben Detailgrad wie das Ursprungsdatum aufweist. Damit lassen sich Berechnungen mit deutlich geringerem Rechenaufwand durchführen, woraus sich geringere Latenzen und eine bessere Energieeffizienz ergibt, da das Rechensystem deutlich weniger Rechenzeit benötigt.
Mehr Leistung und Energieeffizienz mit Intel Xeon Prozessoren der 4. Generation
KI-Workloads und -Applikationen lassen sich mithilfe von Numenta erheblich beschleunigen
Als Folge daraus ergeben sich zwei Konsequenzen: LSTM-Anwendungen wie ChatGPT oder zahlreiche Spracherkennungsprogramme lassen sich mithilfe der Numenta-Technologie deutlich schneller trainieren und ausführen als mit bisherigen Modellen, und das ohne den Einsatz von speziellen Silizium-Komponenten wie GPUs, die teurer sind als herkömmliche Standard-Prozessoren wie die Intel Xeon CPU. Damit lässt sich ein und derselbe Prozessor für das Trainieren und Inferenzieren von KI-Modellen nutzen, und das mit deutlich geringeren Gesamtkosten.
KI-Lexikon: Wichtige Begriffe der Künstlichen Intelligenz erklärt
Disclaimer: Diesen Blogpost habe ich im Auftrag von Intel produziert. Bei der Ausgestaltung der Inhalte hatte ich nahezu freie Hand.